What I learned
This was my first end-to-end RAG project shipped to a real user base. The lesson: most of the work in a “chat with my site” build isn’t the LLM — it’s the ingestion pipeline, the chunk sizing, the source attribution, and the polish to make answers feel native to the brand rather than generic.
I also learned how much guest-experience friction a small chatbot can dissolve. “What time is the ceremony” / “where do I park” / “is there a dress code” — these queries hit at all hours, and the bot resolves them without me reaching for my phone.
What I did
- Built a recursive scraper with Selenium + BeautifulSoup to ingest event details from the source pages.
- Chunked and embedded the content via LangChain + OpenAI embeddings, stored as vectors in Pinecone.
- Served retrieval + answer generation through a FastAPI backend, with source attribution and structured logging at every step.
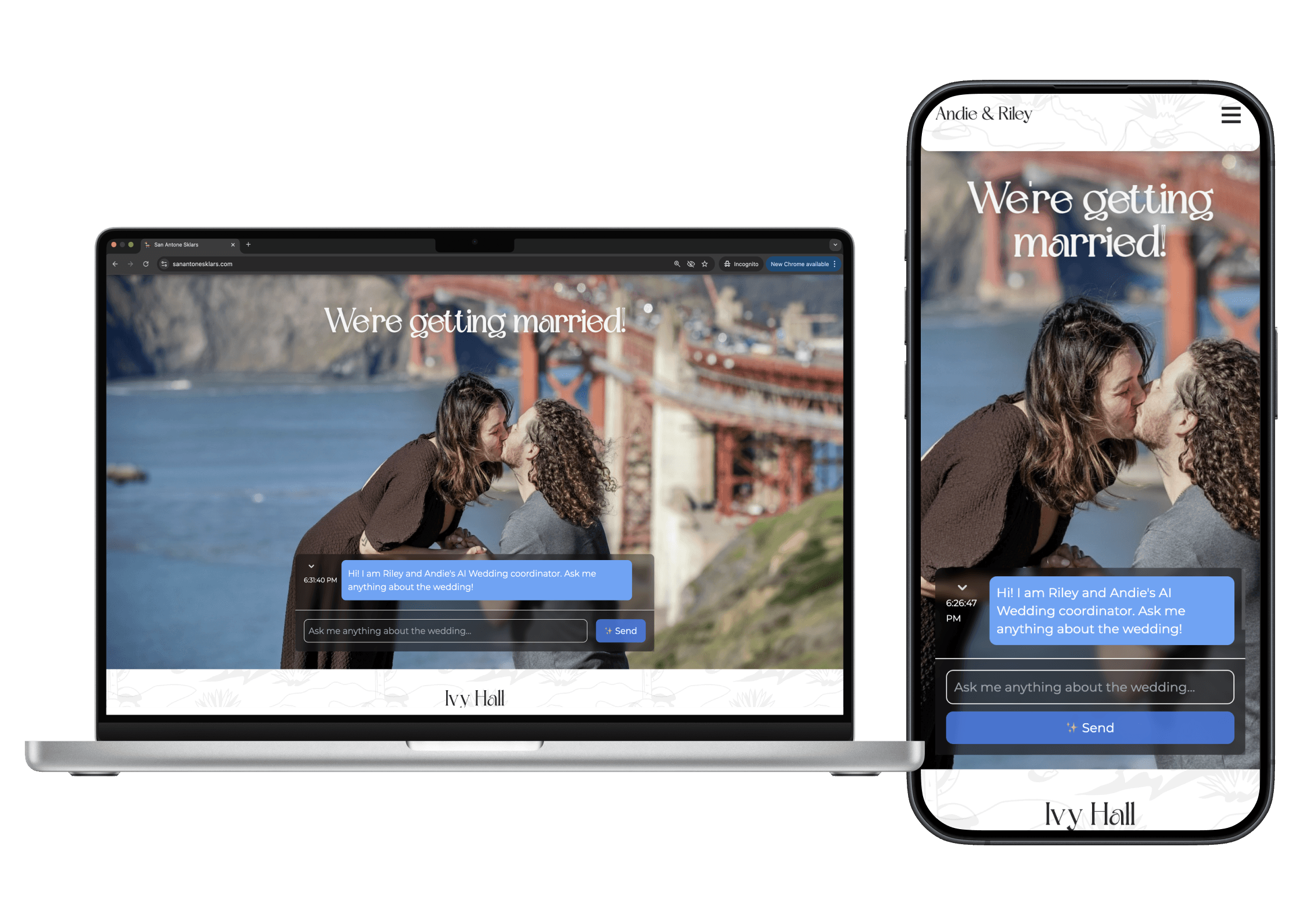
- Wrapped it in a React frontend styled to match the wedding’s brand — so the chatbot reads as part of the experience, not a third-party widget.
What I shipped
A live wedding website with an AI guest-services chatbot at https://sanantonesklars.com. Backend in Python, frontend in React/Astro, content indexed in Pinecone, answers generated by GPT — and a guest experience that’s substantially smoother than the spreadsheet-and-FAQ alternative.